공부했던 내용들을 계속 까먹는 것을 방지하고자,
앞으로 읽게되는 흥미있는 경제학 논문들에 대한 리뷰를
간단히 게시판에 남기려 한다.
논문들을 읽으면서 새롭게 알게되는 기록을 남길 예정에 있으나,
개인 능력부족으로, 이해를 잘못해서
기록을 잘못 남기는 경우도 종종 생길 수 있을 것 같아 걱정이 된다.
혹시라도 이 리뷰를 보게 되는 분들이 계시다면,
그런 부분들을 감안하고 가볍게 읽어주셨으면 한다.
지속적으로 공부해나가면서,
잘못된 내용을 알게 된 경우 본 글의 내용을 바로 다시 수정할 예정이다.
첫 번째로 리뷰해 볼 논문은
Marcelo C. Medeiros, Gabriel F. R. Vasconcels, Alvaro Veiga and Eduardo Zilberman (2019), Forecasting Inflation in a Data-Rich Environment: The Benefits of Machine Learning Methods, Journal of Business & Economic Statistics 이다.
논문 제목에서부터 확실히 드러나듯,
해당 페이퍼는 '다양한 머신러닝 기법과
풍부한 거시경제 월별 데이터 셋(FRED-MD)를 활용하여
미국 인플레이션 예측' 에 관한 연구 내용이다.
그리고 그 결론 내용도 제목에 드러나 있는데,
'풍부한 데이터를 Random Forests 기법을 활용하여 분석하는 경우,
그 예측 결과가 뛰어날 수 있다.'가 해당 논문의 결론이다.
여기서 FRED-MD란 McCracken and Ng(2016)의 연구를 통해
현재 FRED에서 제공하고 있는 미국 거시경제 변수들의 월별 데이터 셋으로,
해당 거시경제 변수들의 안정성(Stationary)을 확보하기 위한 전처리 내용을 상세하게 소개해주고 있어
미국의 거시경제 실증분석을 할 때 큰 도움이 되는 데이터 셋이다.
(데이터 셋 제공: https://research.stlouisfed.org/econ/mccracken/fred-databases/)
저자들은 FRED-MD(vintage 2016.1. 1960.1. ~ 2015.12. 총 672개 관측치) 를 사용했으며,
FRED-MD의 122개 변수에 4가지 주성분을 계산하여 총 126개 변수,
시차를 4차까지 고려하여 총 508개 변수를 분석에 활용했다.
시계열 예측에서 주로 활용되는
Rolling Window framework를 활용하여 예측 및 성과를 평가하였고,
각 모델의 성능 평가는 RMSE, MAE, MAD 로 하였으며,
Giacomini-White test, Diebold-Mariano test 로 그 성능 평가의 차이가 유의한 차이인지 검증하였다.
분석에 사용한 모델은
벤치마크: Random Walk(RW), Autoregressive(AR),
Unobserved Components Stochastic Volatility(UCSV)
LASSO 계열의 변수 선택 모형: LASSO, Adaptive LASSO, Elastic net,
Adaptive Elastic net, Ridge regression
그 외 변수 선택 모형: Bayesian Vector Autoregressive(BVAR)
팩터 모델: Target Factors, Factor Boosting
앙상블 모델: Bagging, Complete Subset Regeressions(CSR),
Jackknife Model Averaging(JMA)
그리고 본 논문의 주인공인 Random Forests 이며,
분석 결과의 강건성(Robustenss)을 검증하기 위해
- 경제적 의사 결정이 실시간으로 이루어지는 것을 감안하여,
2001년부터 2015년까지 실시간 분석을 통해 분석
- 비선형 모델로 Deep Neural Network, Boosted Trees,
Polynomial model estimated either by LASSO or Adaptive LASSO,
linear model estimated with nonconcave penalties (SCAD)를
추가적으로 분석, 그 결과를 확인하였다.
이 연구의 주요 결과는 다음 테이블과 같다.

이 표를 보면 Random Forests(RF)의 성과가 매우 우수하다는 사실을 쉽게 확인할 수 있다.
아마도 Random Forests 모델이 좋은 성능을 보이는 이유는
1. 변수 선택 방식: 따로 변수를 선택하지 않고, 수많은 데이터를 활용한 점
2. 과거 거시경제변수들과 인플레이션간의 비선형 관계의 존재 가능성
때문으로 예상된다.
|
(참고) 본 연구에서 밝힌 거시경제변수들과 인플레이션 간의 비선형 관계에 대한 선행연구 요약
1. 인플레이션과 고용의 비선형성에 대한 연구: 경기 침체의 정도에 따라 그 관계가 상이
2. 경제적 불확실성은 비선형성의 원천:
- 불확실성으로 인해 경제적 의사결정 지연의 옵션 가치가 달라짐
(고용은 불확실성에 대해 비선형적, 해고에 따르는 비용이 달라지기 때문 )
3. 명목금리가 지닌 0의 하한 및 비전통적 통화정책에 대한 영향도
인플레이션과 고용, 금리 변수들 사이의 비선형성의 또 다른 원천 4. 주택 담보 대출 범위 내에서 통화정책 및 금융중개와 상호작용
(대공황 때처럼 주택 거품이 형성되어 심각한 신용붕괴 초래 가능)
이러한 상호작용은 매우 비선형적이며, 인플레이션, 고용 및 금리에 비선형적인 영향을 미침)
|
해당 연구에서는 Random Forests 모델이 왜 풍부한 데이터를 토대로 예측할 때,
우수한 결과를 보여주는지 그 블랙박스를 해부하기 위해 두가지 방향으로 접근했다.
1. 변수 선택을 Adaptive LASSO, Ridge Regession, Random Forests로 실시하여 비교
Ridge regression에서는 Prices, Employments, AR terms 가 중요한 Factors로 나오고 있고,
Adaptive LASSO 에서는 AR terms와 함께 단기에는 Prices,
중기에는 Output-income Variables 가 중요한 것으로 나오고 있다.
반면 Random Forests에서는 disaggreagated prices, interest-exchange rates,
employment, hosing이 중요한 변수로 나오고 있다.
(세가지 모두에서 Stocks는 선택되지 못함)
해당 페이퍼에서는 이 결과를 횡단면 측면의 고차원의 변수 집계가
예측 모델 성능 저하의 원인일 수 있음을 보여주는 결과라고 해석하고 있다.
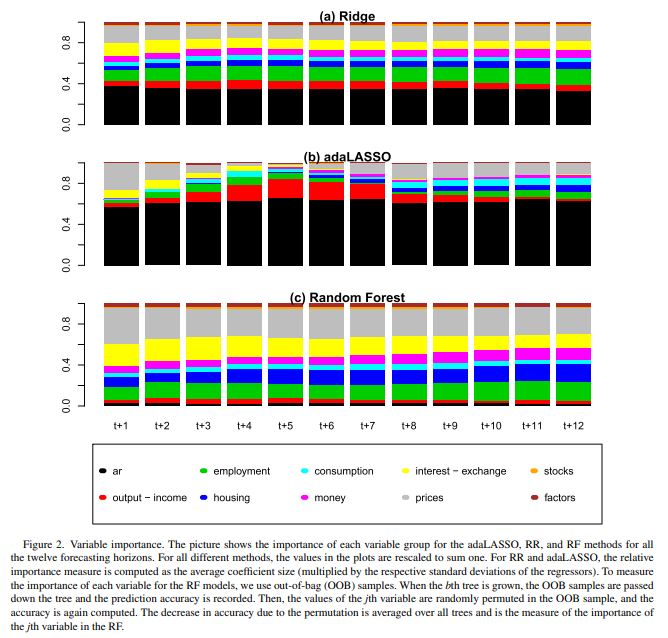
해당 변수 분류는 McCracken and Ng의 분류를 참고
(1. Output and income 2. Labor market 3. Housing
4. Consumption, Orders and Inventories, 5. Money and Credit,
6. Interests and Exchange rates 7. Prices 8. Stock market)
추가로 AR terms와 전 설명변수를 토대로 계산된 Factors들도 활용
2. 변수선택효과를 구분하기 위해 두가지 분석을 추가로 실시하였다.
- Random Forests로 변수 선택 후 OLS로 선형 분석
- Adaptive LASSO로 변수 선택 후 Random Forests로 분석
이 두 모델 모두 근시일의 예측에서는 Random Forests보다 우수한 결과를 보였으나,
그 기간이 길어질 수록 Random Forests의 성능을 따라오지 못했는데,
해당 페이퍼에서는 이를 비선형성과 변수 선택이
Random Forests의 우수성을 보여주는 핵심 키임을 보여주는 부분으로 설명하고 있다.
분명 해당 연구 결과를 볼 때,
Random Forests의 경제 변수 예측력은 상당히 우수해 보인다.
하지만 이 연구 결과의 강건성(Robustness)에 대해서는 의문이 드는 부분이,
'한 가지 분석 방법론이 과연 데이터가 풍부하기만 하면
다른 분석 방법론들을 압도할만한 성과를 꾸준히 보일 수 있을까?' 하는 부분이다.
저자들도 이 부분에 대해서는 언급하고 있는 부분이 있다.
선행연구들에서는 Random Forests가 주목받지 못했으나,
본 연구에서 주인공이 된 이유로,
'과거 연구들에서는 인플레이션이 I(1) 과정이라고 보았으나,
본 연구에서 고려한 기간에서 인플레이션은 I(0) 였다.
애초에 RW, UCSV는 안정적인 데이터를 고려하는 모델에서
그 매력도가 떨어지기 때문에, RF가 이 두 벤치마크보다 성능이 좋게 나온 것일 수도 있음.'
이라는 언급을 추가로 해 둔 부분이 있다.
그렇다면 여기서 궁금해지는 부분이
I(0) 과정을 예측하는데 있어서는
'데이터가 풍부하기만 하면, Random Forests의 예측력이 압도적으로 좋을까?'
하는 부분인데,
이 부분은 연말까지 한국의 데이터를 활용하여 검증 후,
관련 결과를 정리해 볼 예정이다.
'경제학' 카테고리의 다른 글
| [논문리뷰] Bank Runs, Deposit Insurance, and Liquidity (Diamond and Dybvig) (1) | 2022.10.28 |
|---|---|
| [논문리뷰] Deciphering Monetary Policy Board Minutes with Text Mining (Lee et al) (0) | 2022.10.21 |